




By Pat Byrden, former vice president of business development & strategy
In the world of streaming movies and TV, there’s a tension between content providers and viewers. On the one hand, the content provider is incentivized to get the viewer to watch as much content as possible on their platform: If you’re Netflix, you want viewers to watch as much content on Netflix as possible. On the other hand, viewers want to watch what viewers want to watch, and most people don’t care which provider delivers their content. If I want to watch a movie, I don’t really care if it’s Netflix or Disney or HBO or whoever is delivering it to me. If more than one of them carries the content I want, I’ll probably use the one that’s easiest to access.
If you’re a content provider, while the goal is always to reduce churn, what you should really be concerned about is whether your content is easily discoverable. If the discovery process is easy for the viewer, they will naturally gravitate toward your content.
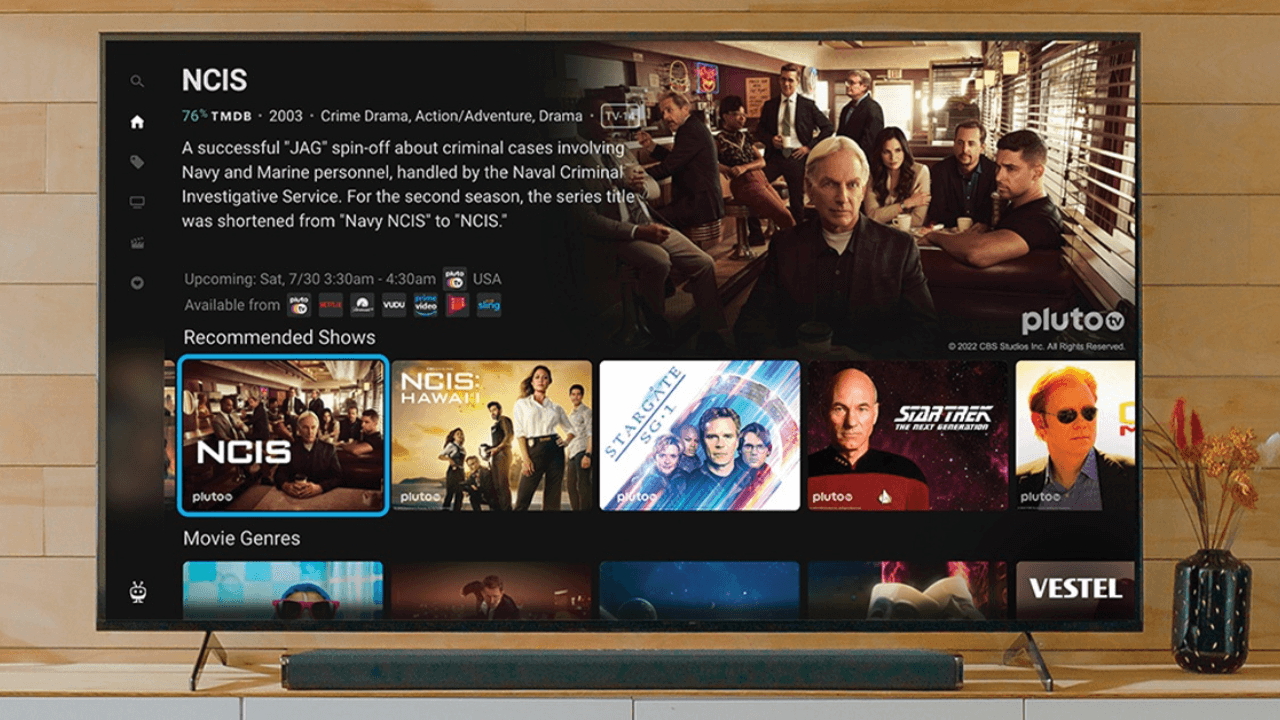
Metadata is one of the most important tools for content discovery, and it is getting more sophisticated all the time.
Content recommendations are traditionally based on metadata. You can read in more detail here about how specific metadata can improve discoverability. That being said, if the quality of the metadata is low, the recommendations aren’t going to be very good.
Now it’s true that some people might go through a phase where they want to watch every film a particular director has made, but most people don’t do that. Metadata-based recommendations have had to become a lot more sophisticated in recent years. One of the most exciting innovations in this area in recent years is the arrival of OS-based content discovery. In short, this is a method of bringing the content discovery process out of the silos of individual content providers and into the OS home screen. This method — which is delivered using powerful metadata — has benefits for users and providers alike, as well as for the TV manufacturers themselves. How does it work?
In the OS environment, metadata is aggregated in the discovery interface. This aggregation helps to unify the experience for the user because people often see different metadata (images, genre, description, etc.) when they go to different content providers. Most operating systems will have a carousel for each provider, so you’ll see a Netflix carousel, a Disney carousel, etc. But in the OS-centered discovery approach, the user will see a recommendations carousel and when they select their content of choice, they’re taken to the movie being shown by their preferred provider.
This has the positive effect of getting users to their content more quickly. We’ve all had that experience of searching for something to watch and it taking several steps to get there. Sometimes it can feel like an endless scroll through different carousels on different provider pages. Often the process feels exhausting as we filter through page after page of suggestions. Eventually, decision fatigue sets in and we sometimes even give up or just go back to watching something old and familiar.
Consumers want to get to content more quickly, and that is the value of the aggregation approach for the content provider as well: consumers have a better experience and end up feeling better about the provider, because their experience was as friction-free as possible. With the OS-based discovery process, we instead are shown a carousel of relevant content based on our interests and viewing history. Deep links on the discovery screen take us directly to the movie. From the provider’s point of view, the quicker you get people to content, the more they watch.
A common issue for viewers is when one provider only carries a few seasons of a particular TV show and the other seasons are carried by another provider. This makes it tricky for a consumer to watch the show because it can be difficult to keep track of which season is carried by which provider. With an aggregation model, the seasons are shown on the discovery page and deep linked to the provider where it is carried. Again, the consumer wants to watch the show and cares less about where it is carried than whether or not they can get to the next episode quickly.
Imagine you’re watching a dramatic show, and the final episode of season three ends with a huge cliffhanger in the plot, it’s not yet bedtime and you want to immediately watch the first episode of season four. However, the provider that carries season four is not the same as the one that carried season three. So, you have to go out and figure out how to navigate to season four on the new provider. With aggregation, you’d just select “next episode” and you’re taken directly there.
Not only are there tremendous benefits to users and providers, but to the OEMs as well. The user has a great simple experience, which leads to brand loyalty. Consumers don’t tend to buy a TV because of the OS that it has, but they tend to stay with a TV (or not) because of the experience on the home screen. If people have a bad experience on the home screen, they usually either plug an external device into the TV — like a Roku stick or a gaming platform — to access content that way or they find another TV. In a world where people are upgrading their TVs less frequently, and where advertising can be an important piece of the revenue puzzle for the OEM, the motivation is in getting a consumer to stick with your platform as long as possible.
A lot of movie and TV show metadata is machine generated, or delivered by the content creator. However, crowdsourced metadata is a key piece of the puzzle, because over time, a vast user base can deliver a richer dataset than any single entity is capable of. The list of new films and TV shows grows every day, making the metadata management challenge something that must constantly adapt to new information. Take TMDB for example even though the site is less than 20 years old, its user base has grown to more than 1.5 million users, who collectively made more than 21 million edits to the database in 2023 alone. That metadata about hundreds of thousands of movies and millions of TV episodes can be used to improve the content discovery process for people using CTV platforms that leverage this metadata. When paired with machine-generated metadata, crowdsourced platforms like TMDB become powerful tools for recommendation and discovery. This metadata can be pulled directly into the CTV OS environment and aggregated in such a way that the user finds relevant content more quickly and can start watching it faster.
Users want to get to their content quickly. Content providers want this too. Good experiences lead to better loyalty for manufacturers. By bringing the discovery process closer to the user and making it easier and quicker to get to watching their content of choice, the OS-based content discovery process removes a lot of the friction in the home entertainment experience, which is simply better for everyone involved.
For more information on TiVo’s metadata capabilities, click here.


